概要

我们知道, C++ 是一个语言联邦,包括 C、Object-Oriented C++、Template C++、STL。OO部分可以说是C++的核心部分,也是最为熟悉与陌生的地方,熟悉是因为每时每刻都在使用,像 C 语言这种过程式的语言,给人感觉总是十分的直接明了,无非就是堆栈建制,函数栈的切换,但是 OO不一样,编译器为我们做了太多的事情,构造,析构,虚函数,继承,多态…或者在member function中加入一些额外参数(this指针),导致我们去计算对象的空间占用、函数调用的性能时,结果往往是意想不到的。
这次就让我们来探索总结一下C++的对象模型,主要参考书籍 <<深度探索 C++ 对象模型>>,作者是C++第一代编译器cfront的编写者之一Lippman,之前看过一遍,工作快三年了,再温故一下,现在看起来感觉轻松很多,我会大致按书中目录顺序进行总结提炼,书总是要越看越薄的,同时,我会使用Linux gcc编译器去测试书中的demo程序,看一下 gcc 编译器究竟是如何设计 C++对象模型的。
本章内容分为:
C++对象模型的整体设计C++对象模型内存分布(Data member语意)C++对象模型Function语意RTTI(Runtime Type Identification)
深入理解C++对象模型,主要是让我们在编写相关程序时,能编写出更加高效且不包含错误倾向的代码,同时对C++编程更有信心,引用侯捷老师的话就是,能够做到胸中自有丘壑。
系统环境
- gcc 版本 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC)
- Linux yejy 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
文章中相关模型图片也会借鉴书籍中的,不是我自己不想作图哈,只是已经有现成的,借鉴一下就可以了。UML类图、时序图、流程图、思维导图等,可以很好的让我们理解设计模型,从而发现其中的设计缺陷并完善之,非常有帮助。下面是我在熟悉一个线程池设计时,做的UML类图,图一出来,整体的设计就清晰了。

C++ 对象模型的整体设计
对于C++对象模型,书中有提到两个概念来解释:
- 语言中直接支持面向对象程序设计的部分
- 对于各种支持的底层实现机制
对于第一点,在各种C++程序书中都有介绍,至于第二点,则是本书介绍的重点,市面上介绍C++面向对象底层实现机制的书籍非常少,好书就更少了。
在C++中,有两种class data members:static 和 nonstatic, 以及三种 class member functions: static 、nonstatic 和 virtual。如下 Class point:
1 |
|
那么编译器是如何构建这个类中的 data members 和 function members呢?
首先,书中引出了第一个简单对象模型,每个data members 和 function members都有自己的一个 slot(槽),按声明顺序排列,每个槽里面放的是指向成员的指针,而不是成员本身,这样是为了避免”members 有不同的类型,因而需要不同存储空间”招致的问题, 该模式一个优点就是简单,并且引入了索引或slot的概念。

然后根据前面的slot概念,又提出了表格驱动对象模型,把data members 和 function members分别放到两张table中,对象则持有指向两张表的指针,data members table 中的slot保存数据本身, function members table中的slot保存函数指针,该模型主要是引出了 member function table, 为支持virtual function提供了一个有效的方案。

前面两个模型出现的主要问题,一个是引入指针过多,空间浪费严重,另一个则是添加的索引层次过多,导致数据存取性能较低,C++ 对象模型则在前两种模型基础上,对内存空间和存取时间做了优化,主要缺点是所用到的 class objects 的nonstatic data members有所修改(有可能是增加、移除或更改),那么应用程序代码同样得重新编译。
在 C++ 对象模型中,Nonstatic data members 被放置于每一个类对象之内,static data members放在类对象之外,然后Static 和 nonstatic function members 也放在了类对象之外。模型图如下:
其中 Virtual functions 通过这两个步骤支持:
1. 每个 class产生一堆指向virtual functions的指针,放在表格中,这个表格就是virtual table(vtbl)。
2.每一个class object被安插一个指针,指向相关virtual table。通常该指针被称为vptr。vptr的设定和重置都由类的constructor,destructor和copy assignment运算符自动完成。每一个class所关联的type_info object(用以支持 RTTI)也经由virtual table被指出来,通常放在表格的第一个slot(位置视编译器而定,也可能不在virtual table中)。
那加入继承,如何支持? 书中作者和我们讨论了几种可行的解决方案,并且分析了各自优劣。
1.之前介绍过的
简单对象模型。slot中直接包含一个base class subobject(继承关系中,父类所拥有的内容)的地址。
主要优点:class object的大小不会因其base classes的改变而受影响 缺点:间接性导致的空间和存取时间上的额外负担2.
base table模型。每一个base class table中内含一个slot包含有相关base class的地址(bptr),
主要优点:
- 在每一个
class object中对于继承都有一致的表现形式:每个class object都需要在固定位置放一个base class table指针,与base class的大小和个数无关- 无需改变
class object本身,就可以放大、缩小,或者更改base class table缺点:间接性导致的空间和存取时间上的额外负担
base table示意图: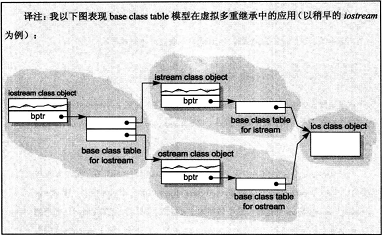
我们知道当前 C++ 编译器处理一般继承是将父类中的data members(包括父类的vptr)直接放到子类中,缺点是base class一修改,子类就需要重新编译;对于virtual base class则引入间接访问性(引入指针,后续介绍)。如下列一般继承关系:

子类直接获得父类的内容(不是virtual base class),相应的内存分布如下:

C++ 对象模型内存分布(Data member 语意)
首先,我们自己测试一下C++对象的大小,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class Base
{
public:
int ib;
char cb;
static int is;
public:
Base() : ib(0), cb('B') {}
virtual void af() { cout << "B::af()" << endl; }
virtual void bf() { cout << "B::bf()" << endl; }
virtual void cf() { cout << "B::cf()" << endl; }
};
int Base::is = 10;
class Derive : public Base
{
public:
int id;
char cd;
public:
void bf() { cout << "derive::bf" << endl; }
};
class Empty
{
};
int main()
{
int *ptr;
cout << "data size, "
<< "int:" << sizeof(int) << " "
<< "float:" << sizeof(float) << " "
<< "char:" << sizeof(char) << " "
<< "ptr:" << sizeof(ptr) << " "
<< endl;
Base b;
Derive derive;
Empty empty;
cout << "Base class size: " << sizeof(b) << endl;
cout << "Derive class size: " << sizeof(derive) << endl;
cout << "empty class size: " << sizeof(empty) << endl;
}
最后打印结果分别为 16 字节和 24 字节、1 字节,知道为什么吗?C++ 对象模型的空间大小主要受到三个因素的影响:
1. 语言本身所造成的额外负担。当语言支持 virtual base classes时,就会导致额外负担,需要提供一个指针,它可能指向virtual base class subobject,或者指向一个表格(V-table)。
2.编译器对特殊情况提供的优化处理。某些编译器会对empty virtual base class提供特殊支持,通常1个字节大小。
3.Alignment的限制。字节对齐影响,数据结构体的总大小通常32位系统为4的倍数,64位系统为8的倍数。
alignment就是将数值调整到某数的整数倍。通常32位系统alignment为4 bytes,64位系统为8 bytes, 以使bus的运输量达到最高效率。
根据上述三条规则,我们可以看出结果是对的, gcc 编译器,对于空的类,会提供 1 字节的空间大小,主要是为了保证在内存中的唯一性,便于区分;基类 Base 的static data member大小不包含在内,int 4 + char 1 + vptr 8 + alignment 3 总共 16 字节;Derive则是在基类的基础上在加了 8 字节,16 + int 4 + char 1 + alignment 3。
如果是多重继承,道理也是类似的。

相应的内存分布:

我们从图中可以看出,多重继承且均存在多态时,会出现多个vptr。
和之前存在较大差异的,主要是虚拟菱形继承,为了保证在每个子类中只存在一份base class subobject内容,编译器不得不为其加入一些间接访问特性(额外指针)。
代码大致如下:

继承关系:
编译器又是如何处理这种情况的呢?书中对该问题进行了探讨,总结起来主要有两种方式。
以指针指向
base class的实现模型

该模型存在两个缺点,一是每个对象必须为其每个virtual base class背负一个额外指针。二是由于虚拟继承的串链的加长,导致间接存取层次的增加,意思是如果存在三层虚拟继承,我就需要三次间接存取(经由三个virtual base class)。
为了解决上述第一个问题,微软编译器是引入了一个virtual base class table,object 只需要保存一个指向该表的指针,表中则保存一个或者多个virtual base class。
第二个方法,则是C++之父Bjarne比较喜欢的方法,在virtual function table中放置virtual base class的offset。也是间接调用,只是用的偏移地址。

这大概就是书中对虚拟继承的主要讨论,为了节约空间,就必须引入间接特性,牺牲一些调用性能,现在的编译器对于该问题的实现方式都是大同小异。
C++ 对象模型 Function 语意
这一节,我们主要探讨一下C++对象模型中的函数调用,也就是虚函数表(v-table)。
还是上面那部分代码示例,我们做一下其他测试。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67class Base
{
public:
int ib;
char cb;
static int is;
public:
Base() : ib(0), cb('B') {}
virtual void f() { cout << "B::f()" << endl; }
virtual void g() { cout << "B::g()" << endl; }
virtual void h() { cout << "B::h()" << endl; }
};
int Base::is = 10;
class Derive : public Base
{
public:
int id;
char cd;
public:
void g() { cout << "derive::g" << endl; }
};
int main()
{
// 检测对象的vptr是在对象尾地址还是首地址
if ((int *)&b == (int *)&b.ib)
{
cout << "vPtr is in the end of class object: " << (int *)&b.ib << endl;
}
else
{
cout << "vPtr is in the head of class object: " << (int *)&b << " " << (int *)&b.ib << " " << (int *)&b.cb << endl;
}
typedef void (*Func)(void);
cout << "Derive: " << endl;
Base *d = new Derive();
long *vptr = (long *)*(long *)d; // 64 位系统, 指针长度为8字节, 首先获取到 v-table 的首地址
Func f = (Func)vptr[0]; // 通过函数指针转型
Func g = (Func)vptr[1];
Func h = (Func)vptr[2];
f();
g();
h();
cout << "Base: " << endl;
Base *base = new Base();
long *vptr1 = (long *)*(long *)base; // 基类 v-table
Func f1 = (Func)vptr1[0];
Func g1 = (Func)vptr1[1];
Func h1 = (Func)vptr1[2];
f1();
g1();
h1();
return 0;
}
我们首先测试一下对象中的vptr是在头部还是尾部,书中虚表指针有的是存放在类对象的头部,有的是存放在尾部, 这个视编译器而定。
程序打印如下:1
2
3
4
5
6
7
8
9
10
11vPtr is in the head of class object: 0x7ffef49f9890 0x7ffef49f9898 0x7ffef49f989c
Derive:
B::f()
derive::g
B::h()
Base:
B::f()
B::g()
B::h()
从打印结果得知 gcc 编译器的vptr是放在对象头部的,而且看最后的打印结果,我们可以知道对象和虚表结构大致如下:


我们还可以通过gdb去打印一下相关虚表的地址,和具体虚函数的地址进行比对,来看一下虚函数表的具体运作。1
2
3
4(gdb) p (long *)vptr[0]
$2 = (long *) 0x400f60 <Base::f()>
(gdb) info line 61
Line 61 of "main.cpp" starts at address 0x400f60 <Base::f()> and ends at 0x400f6c <Base::f()+12>.
至于多重继承和多重虚拟继承,调用方法类似,只是包含多个vptr,也都是通过vptr索引到相应的V-table,然后执行对应槽中的函数,这些都是在编译期就确定好的。
RTTI (Runtime Type Identification)
C++的RTTI机制提供了一个安全的downcast设备, 但只对那些展现多态(也就是使用继承和动态绑定)的类型有效,那么编译器是如何知道这个类是符合多态的呢? 没错,就是通过声明一个或者多个 virtual functions 来区分,在C++中,一个具备多态性质的 class,正是内含着继承而来的virtual functions。
实现上只需将与符合多态 class相关的RTTI object地址放进virtual table中,通常放在表的第一个位置,gcc下,我们可以通过虚函数表的-1项来访问。
C++ 提供了两个运算符 dynamic_cast 和 typeid 来进行 RTTI 操作。
typid 使用结合虚函数表访问 -1项,进行类型对比,会发现类型是一致的。1
2
3
4
5
6
7
8
// 其余代码同前面
// 获得type_info对象的指针,并调用其name成员函数
cout << "\t[-1]: "
<< ((type_info *)(vptr1[-1]))->name()
<< " "
<< typeid(base).name()
<< endl;
打印如下:1
[-1]: 4Base P4Base
打印结果中出现一些其他字符,如4,P4,是由于C++为了保证每一个类在程序中都有一个独一无二的类名,所以会对类名通过一定的规则进行改写,是正常的。
dynamic_cast 转型操作1
2
3
4
5
6
7
8
9//其余代码同上
Base *d = new Derive();
// 向下转型,判断是否转型成功
// d 要有虚函数,否则会编译出错
Derive* dd = dynamic_cast<Derive *>(d);
if(NULL != dd)
{
dd->g();
}
总结
整体上看,我们会发现,如果不考虑virtual function和虚拟继承的影响,当数据都在同一个访问标识符下,C++的类与C语言的结构体在对象大小和内存布局上是一致的,C++的封装并没有带来空间时间上的影响。对于虚函数和虚拟继承,我们使用时需要知道它会给我们带来哪些额外负担,以此更好的评估是否需要将其引入,通过上面的总结与分析,C++对象模型应该就大致清楚了。当然<<深度探索 C++ 对象模型>>的书中很多讨论分析方案,虽然最终没有引入到实际中来,但是其分析的思路是很有价值的。
参考
<<深度探索
C++对象模型>>
https://www.tuicool.com/articles/iUB3Ebi
https://coolshell.cn/articles/12165.html
https://www.cnblogs.com/hushpa/p/5707475.html
https://blog.csdn.net/ljianhui/article/details/46487951